Why Simulation Datasets Matter
Simulation datasets transform simple Q&A testing into realistic conversation testing:| Benefit | Description |
|---|---|
| Goal-Oriented Testing | Test whether your agent achieves specific objectives, not just individual responses |
| Persona-Based Scenarios | Simulate different user types—frustrated, confused, friendly, or neutral |
| Multi-Turn Conversations | Test how your agent handles back-and-forth dialogue (1-10 turns) |
| Fact Verification | Ensure your agent communicates critical information correctly |
| Context Simulation | Provide user data and context for realistic scenario execution |
Dataset Dashboard
Navigate to Evaluation → Datasets from the left navigation panel. Filter by Multi turn type to see simulation datasets.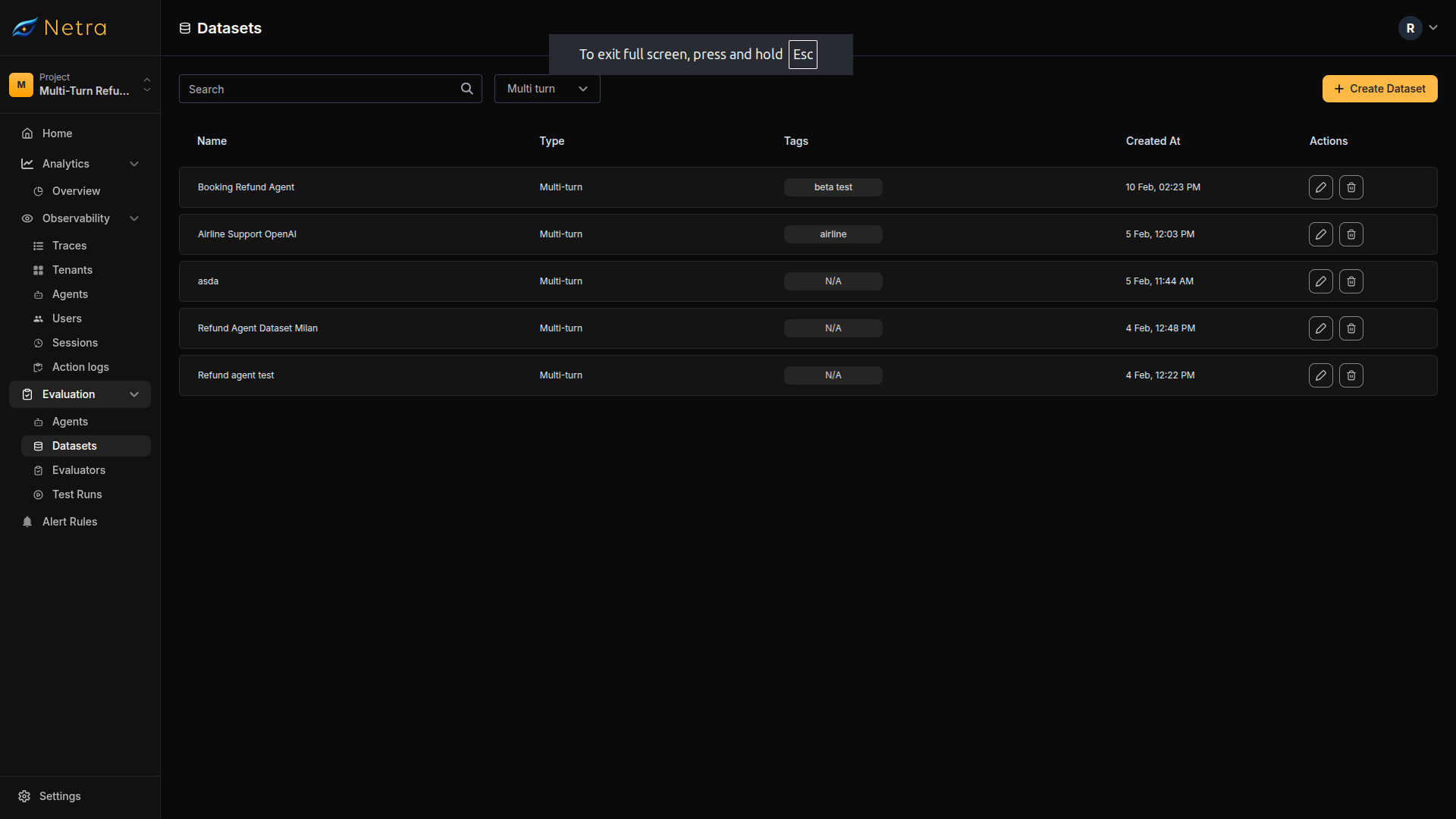
| Column | Description |
|---|---|
| Dataset Name | Unique identifier for the simulation suite |
| Turn Type | MULTI for simulation datasets |
| Tags | Metadata labels for filtering and organization |
| Created At | Timestamp for version tracking |
| Actions | Quick access to edit or delete datasets |
Creating a Multi-Turn Dataset
Click the Create Dataset button in the top right corner of the Datasets page.Configure Basics
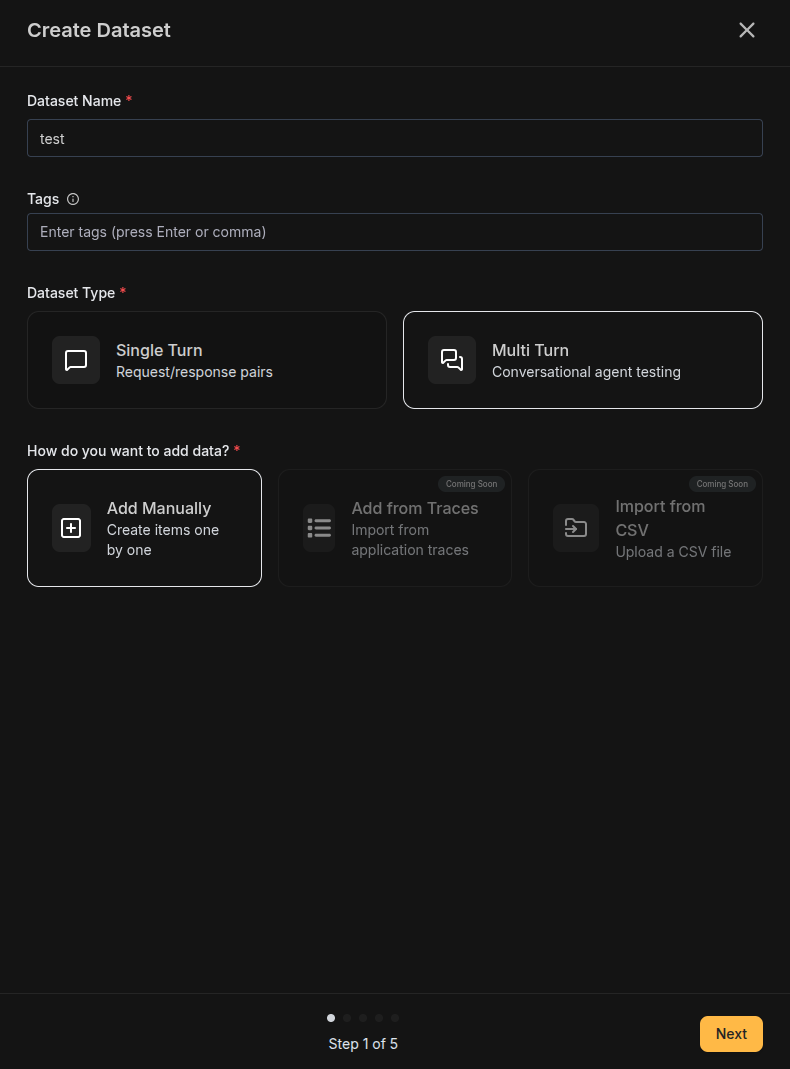
| Field | Description |
|---|---|
| Name | A descriptive identifier for your simulation suite (e.g., “Customer Refund Scenarios”) |
| Tags | Labels for filtering (e.g., “customer-support”, “refunds”, “production”) |
| Type | Select Multi-turn for simulation scenarios |
| Data Source | Select Add manually to create scenarios one by one |
Import from traces and CSV import for multi-turn datasets are coming soon.
Configure Scenario
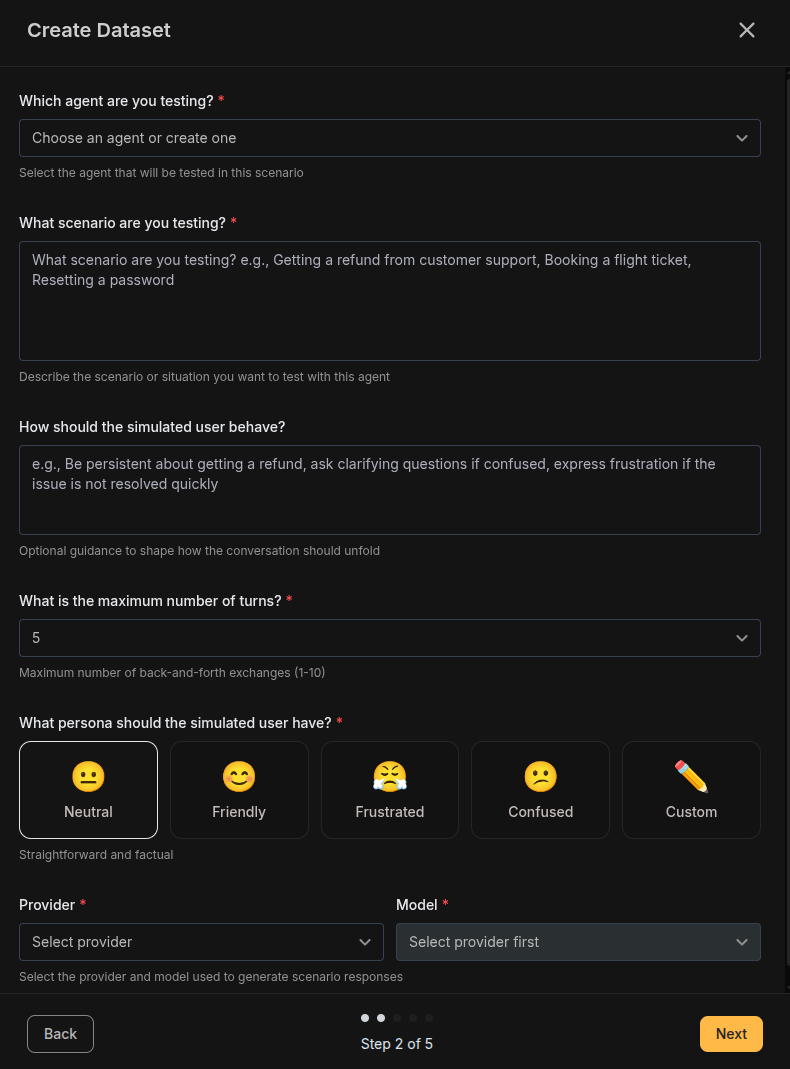
- Lower (1-3): Quick interactions like single-question support
- Medium (4-6): Standard support conversations
- Higher (7-10): Complex, multi-step problem resolution
| Persona | Icon | Description |
|---|---|---|
| Neutral | 😐 | Straightforward and factual, sticks to the point |
| Friendly | 😊 | Polite and cooperative, patient with the agent |
| Frustrated | 😤 | Impatient, wants quick resolution, may be curt |
| Confused | 😕 | Needs extra clarification, asks follow-up questions |
| Custom | ✏️ | Define your own persona behavior |
Add User Data and Facts
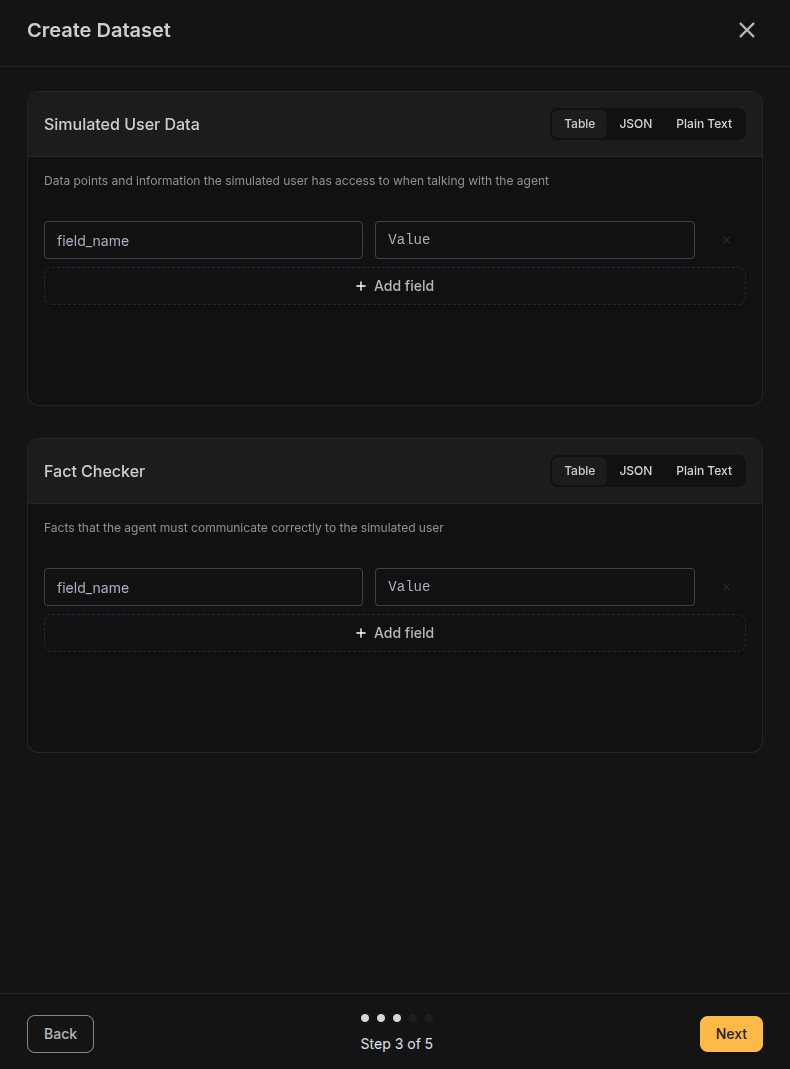
| Key | Value |
|---|---|
| order_number | ORD-123456 |
| purchase_date | 2024-01-15 |
| product_name | Wireless Headphones |
| order_total | $129.99 |
| shipping_address | 123 Main St, New York, NY |
| Fact | Expected Value |
|---|---|
| refund_processing_time | 5-7 business days |
| refund_method | Original payment method |
| return_label_delivery | Within 24 hours via email |
Select Evaluators
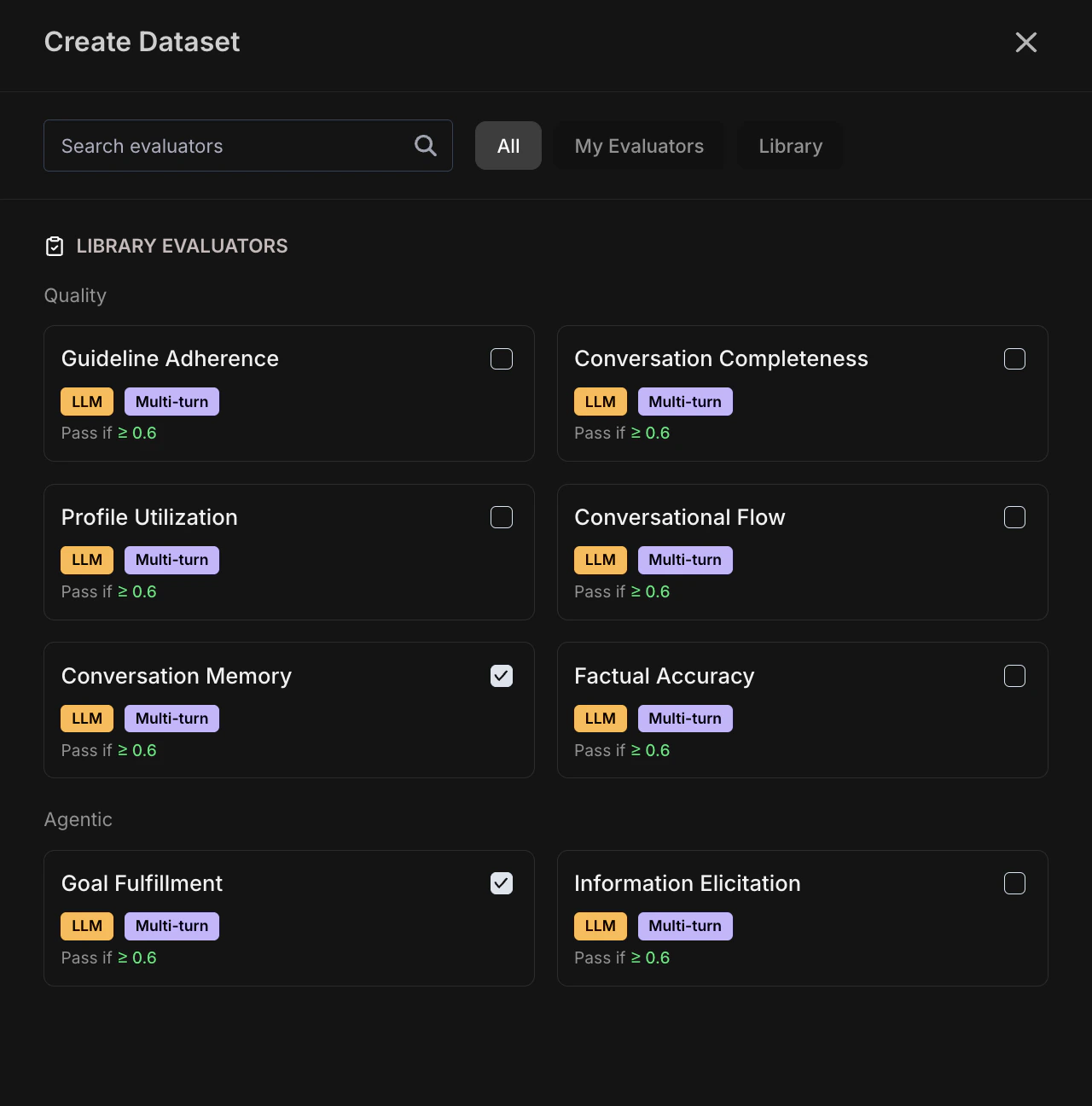
- Agentic: Goal Fulfillment, Information Elicitation
- Quality: Factual Accuracy, Conversation Completeness, Guideline Adherence
- Scenario fields: Goal, persona, user data
- Agent response: What the agent said in each turn
- Conversation metadata: Turn index, conversation history
- Execution data: Latency, tokens, model
Configure Evaluators
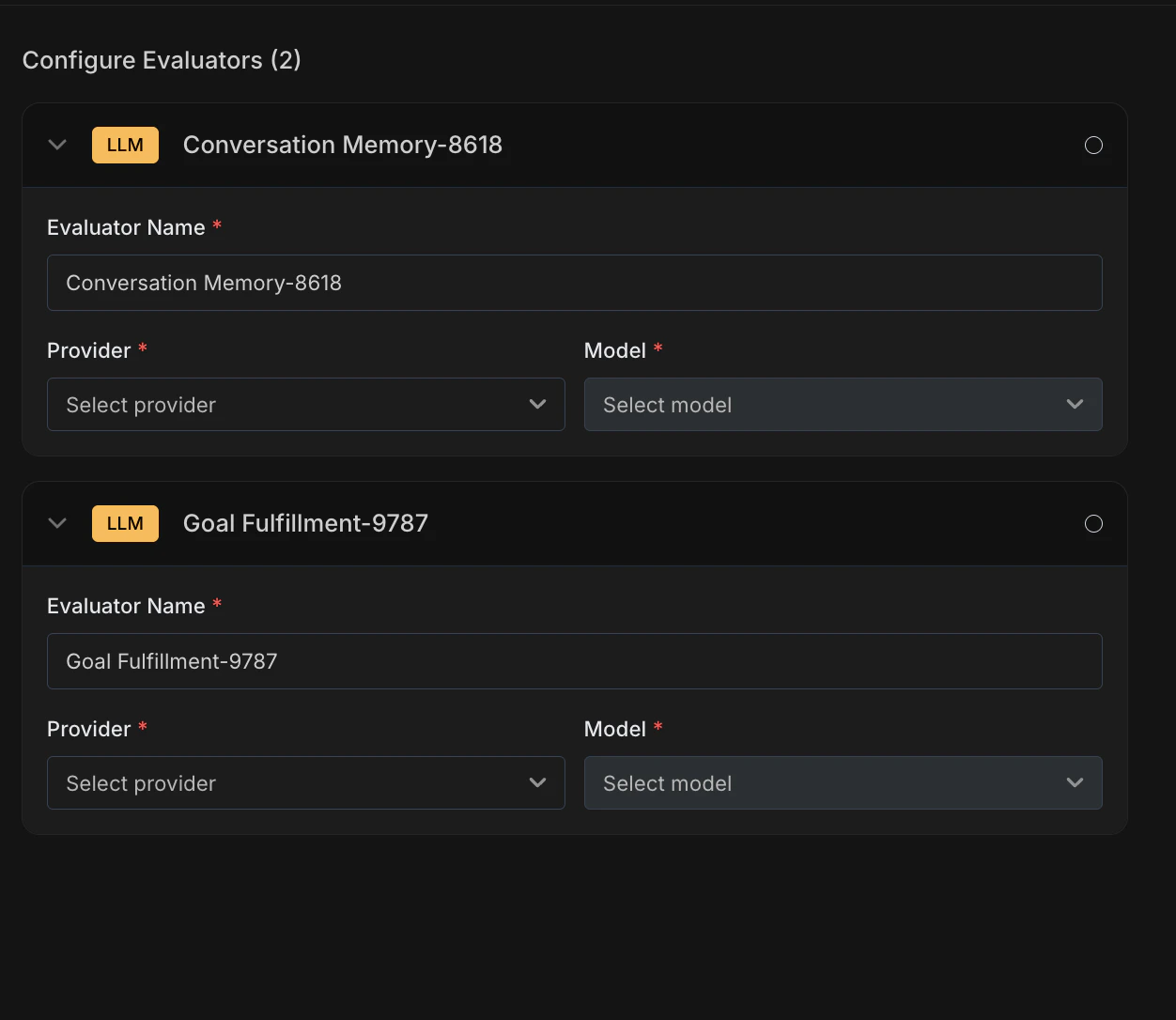
- Rename (optional) — Rename any evaluator to match your use case (e.g., “Refund Goal Fulfillment” instead of “Goal Fulfillment”)
- Select Provider and Model — For each evaluator, choose the provider and model that will run the LLM-as-Judge evaluation (e.g., OpenAI / GPT-4.1)
Running a Simulation
Once your dataset is configured, you can run simulations: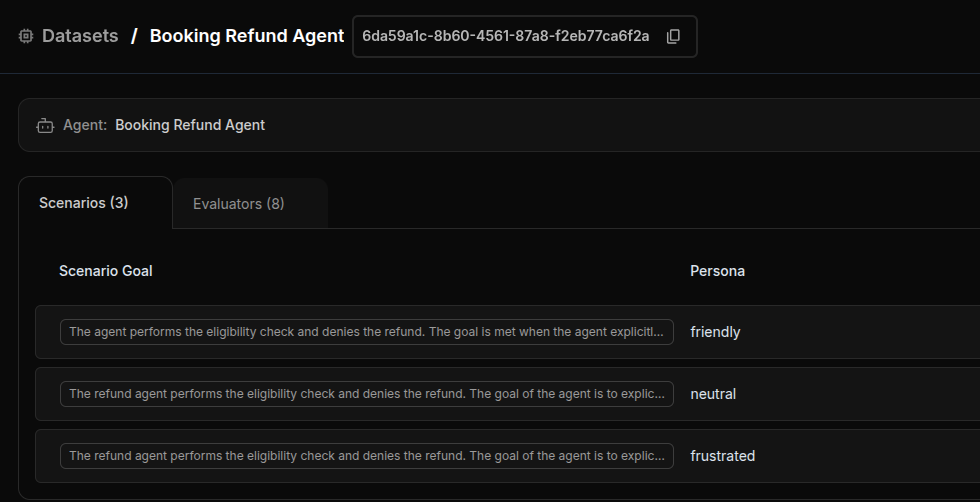
Trigger Simulation
Use the Dataset ID in your simulation code. The simulation runs automatically
through the Netra SDK.
View Results
Monitor progress and results in Test Runs.
Best Practices
Crafting Effective Scenarios
- Be specific: “Get a refund for a damaged product” is better than “Ask about returns”
- Include context: Provide enough detail for realistic simulation (order details, timeline, issue description)
- Include edge cases: Create scenarios that challenge your agent’s boundaries
Choosing User Personas
- Neutral: Best for baseline performance testing
- Friendly: Tests whether your agent maintains professionalism even when not challenged
- Frustrated: Critical for customer support agents—tests patience and de-escalation
- Confused: Tests clarity and explanation quality
- Custom: Use for industry-specific personas (technical users, non-native speakers, etc.)
Defining User Data
- Provide realistic data: Use representative order numbers, dates, and values
- Include edge cases: Test with missing fields, unusual values, or conflicting data
- Keep it relevant: Only include data that matters for the scenario
- Use consistent formats: Standardize date formats, currency, and naming
Setting Fact Checkers
- Focus on critical facts: What MUST the agent communicate correctly?
- Be precise: “5-7 business days” is better than “about a week”
- Test compliance: Include regulatory or policy-critical information
- Verify, don’t duplicate: Don’t repeat information already in user data
Related
- Simulation Overview - Understand the full simulation framework
- Evaluators - Configure scoring logic for simulations
- Test Runs - View simulation results and conversation transcripts
- Traces - Debug simulation turns with execution traces