Why Datasets Matter
Datasets transform ad-hoc testing into systematic quality assurance:| Benefit | Description |
|---|---|
| Reproducibility | Run the same tests across model updates, prompt changes, and code releases |
| Real-World Coverage | Convert production traces into test cases that reflect actual user behavior |
| Regression Detection | Compare results over time to catch quality degradation early |
| Objective Benchmarking | Measure performance against defined criteria, not gut feeling |
Dataset Dashboard
Navigate to Evaluation → Datasets from the left navigation panel to access your datasets.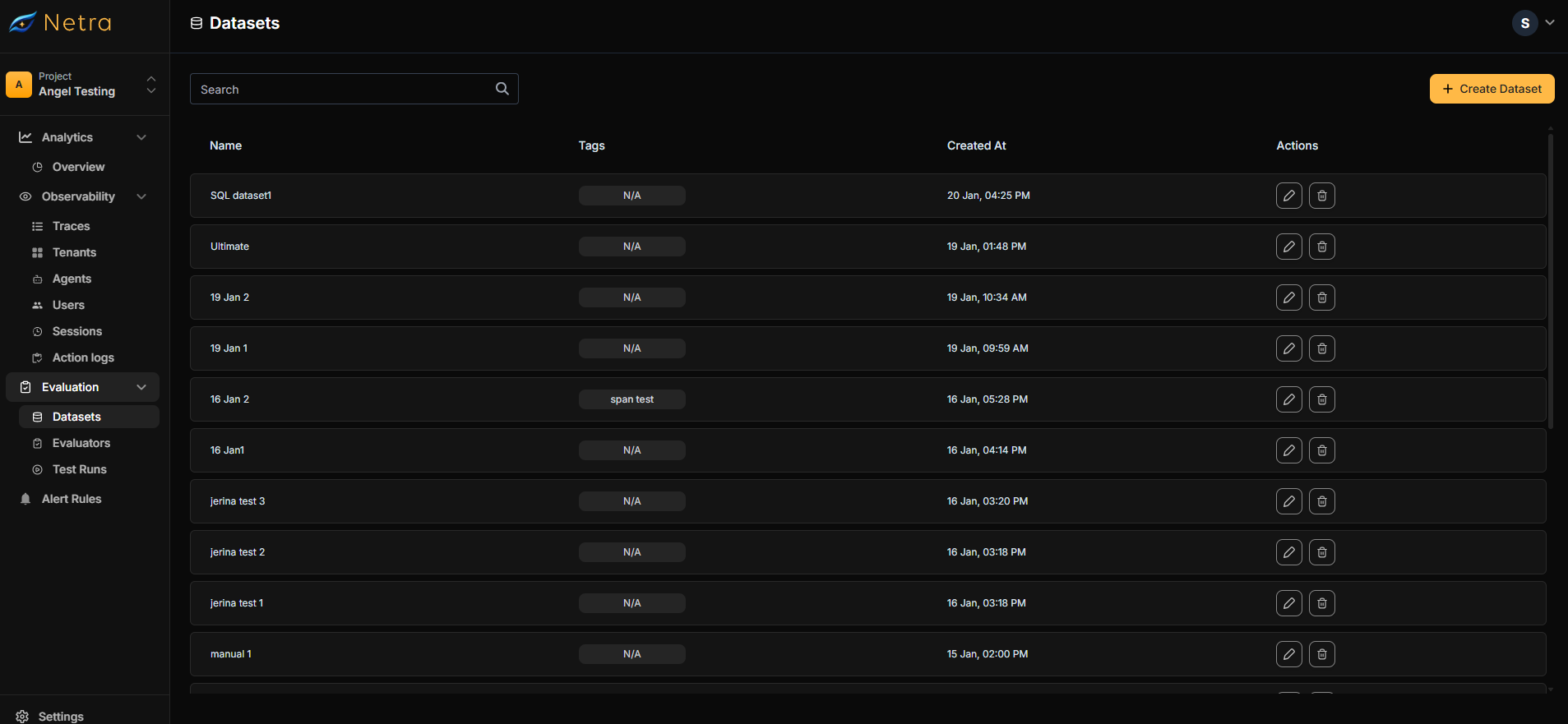
| Column | Description |
|---|---|
| Dataset Name | Unique identifier for the test suite |
| Tags | Metadata labels for filtering and organization |
| Created At | Timestamp for version tracking |
| Actions | Quick access to edit or delete datasets |
Creating a Dataset
There are two ways to create a dataset:From Traces
Convert real production interactions into test cases (Recommended)
Manual Creation
Build test suites from scratch in the dashboard
Creating Dataset from Traces
The fastest way to build meaningful test cases is to capture real interactions from your production system. This ensures your evaluations reflect actual user behavior.Find a Trace
Navigate to Observability → Traces and locate an interaction you want to use as a test case.
Add to Dataset
Click the Add to Dataset button on the trace.Choose to create a new dataset or add to an existing one.
Configure Test Case
In the creation form:
- Enter a dataset name (e.g., “Customer Support QA”)
- Add optional tags for organization
- Review and edit the input prompt
- Provide the expected output
- Include any relevant metadata from the trace
Select Evaluators
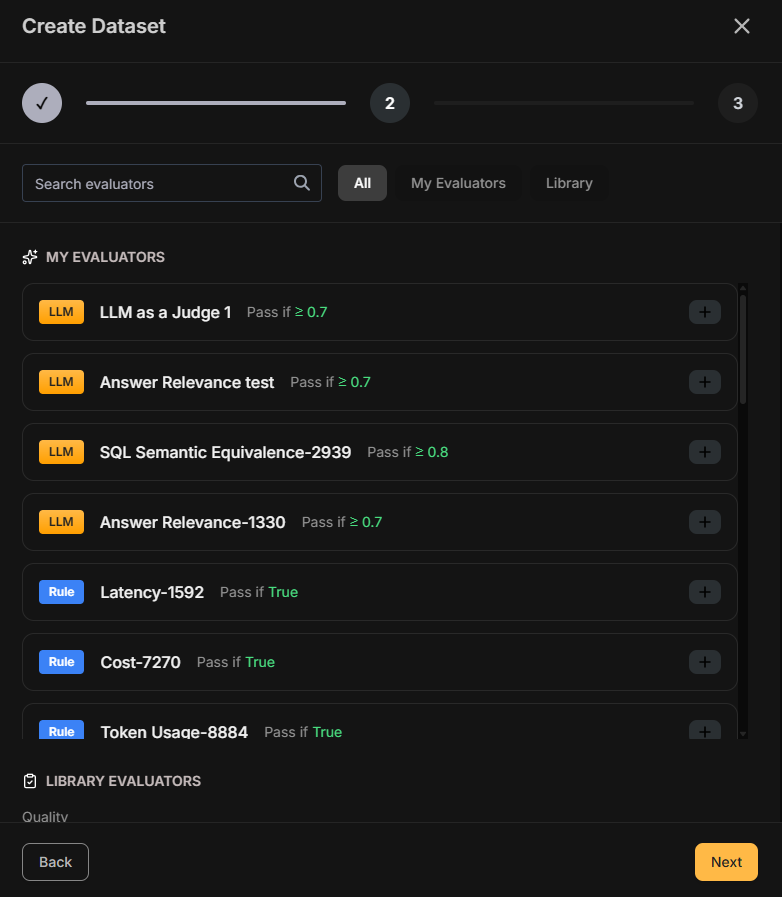
Click Next and choose evaluators to score this test case:
- Browse the evaluator library
- Or select from your saved evaluators in My Evaluators
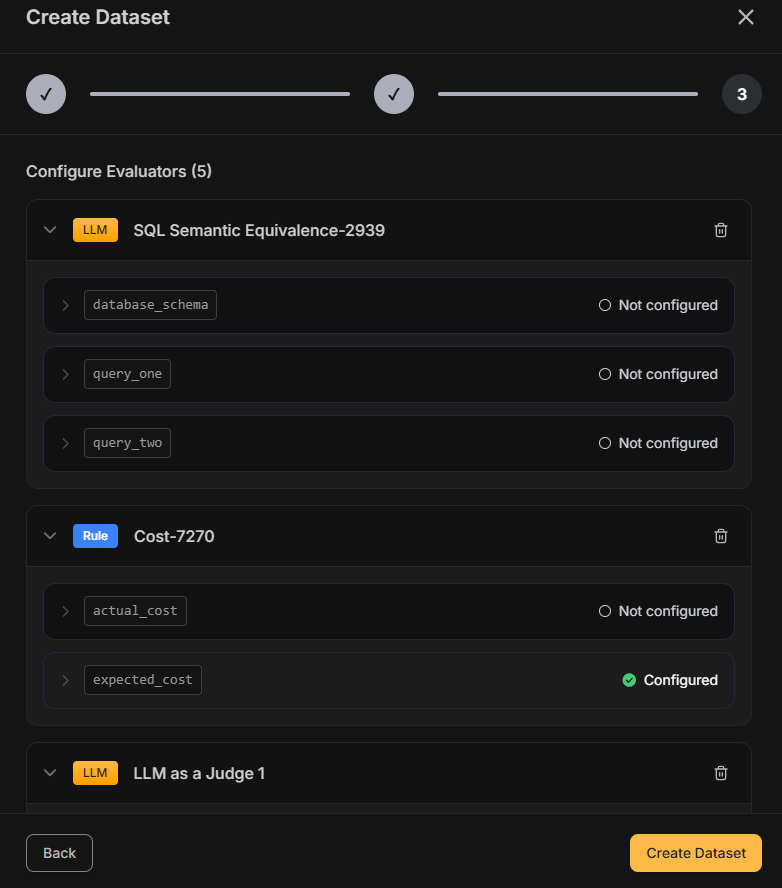
Map Variables
Configure how evaluator variables connect to your data:
| Source | Use Case |
|---|---|
| Dataset field | Use values defined in your test case (input, expected output) |
| Agent response | Use the actual LLM output at evaluation time |
| Execution data | Use metadata from the trace (latency, tokens, model) |
Creating Dataset from Dashboard
For comprehensive test coverage, create datasets manually with carefully crafted test cases.Configure Dataset
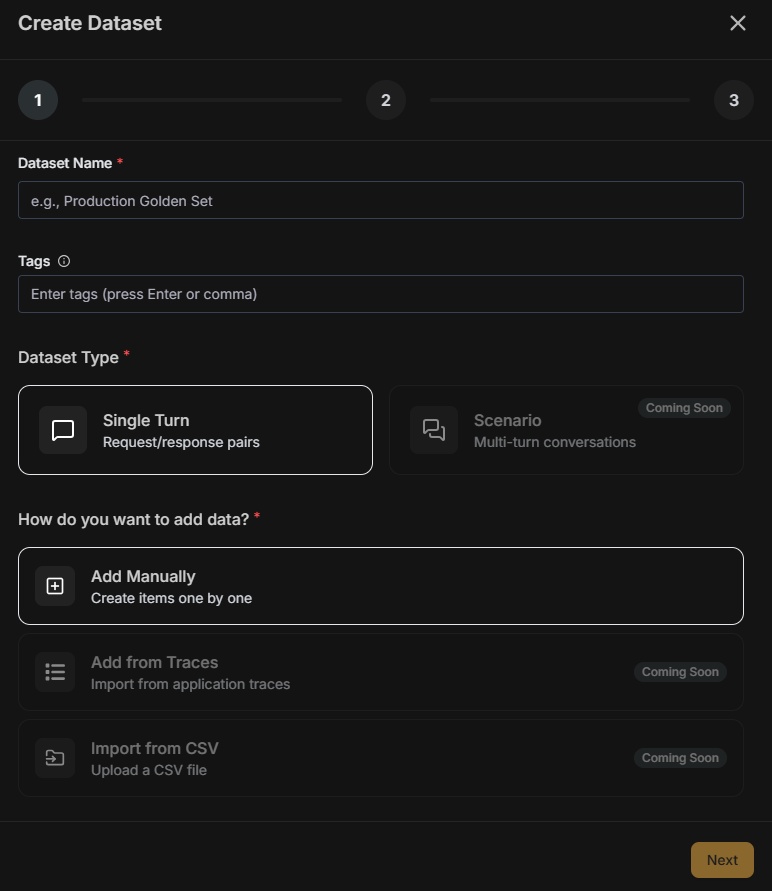
| Field | Description |
|---|---|
| Name | A descriptive identifier for your test suite |
| Tags | Labels for filtering (e.g., “production”, “edge-cases”, “v2-prompts”) |
| Type | Single Turn for request/response pairs |
| Data Source | Add manually to create items one by one |
Scenario (multi-turn conversations), Import from traces, and Import from CSV are coming soon.
Select Evaluators
Running an Evaluation
Once your dataset is configured with evaluators, trigger a test run via the SDK.
Trigger Evaluation
Use the Dataset ID to fetch the dataset and run a test suite. The task function receives the The output is compared against
input field from each dataset item and should return the generated output as a string.expectedOutput by the evaluators attached to the dataset. See the SDK reference for Python and TypeScript for the full API.View Results
Monitor progress and results in Test Runs.
Best Practices
Organizing Datasets
- Use descriptive names: “Customer Support - Refund Requests” is better than “Dataset 1”
- Tag consistently: Create a tagging convention (e.g., by feature, model version, or test type)
- Version your datasets: Include version numbers in tags when testing prompt iterations
Building Effective Test Cases
- Cover edge cases: Include unusual inputs, long prompts, and potential failure scenarios
- Balance quantity and quality: A smaller dataset of high-quality test cases beats a large dataset of weak ones
- Include negative tests: Add cases where the expected behavior is to refuse or ask for clarification
Maintaining Datasets
- Update regularly: Add new test cases from production traces as you discover new patterns
- Remove outdated cases: Delete test cases that no longer reflect current requirements
- Review failed cases: Investigate failures to determine if the AI is wrong or the expected output needs updating
Related
- Evaluation Overview - Understand the full evaluation framework
- Evaluators - Configure scoring logic for your datasets
- Test Runs - Analyze evaluation results
- Traces - Source data for creating datasets from production