Why Evaluators Matter
Without systematic scoring, you can’t measure improvement or catch regressions:| Challenge | How Evaluators Help |
|---|---|
| Subjective quality | LLM as Judge provides consistent, scalable assessment |
| Format validation | Code Evaluators enforce JSON schemas, regex patterns, and business rules |
| Safety compliance | Guardrail evaluators detect toxic, harmful, or off-topic content |
| Tool execution | Agentic evaluators verify correct function calling sequences |
Evaluator Types
Netra offers two approaches to scoring, each suited for different use cases:LLM as Judge
Best for subjective quality, semantic correctness, and nuanced criteria. Uses AI models to evaluate AI outputs.
Code Evaluator
Best for deterministic checks—JSON validation, regex matching, calculations, and custom business logic in JavaScript or Python.
Auto Evaluation
When a trace contains an LLM call, Netra automatically scores the response using three built-in evaluators — no datasets, test runs, or configuration required.| Evaluator | What It Measures |
|---|---|
| Coherence | Is the response well-structured, logically organized, and free of contradictions? |
| Factual Accuracy | Is the response factually correct based on the provided context? |
| Toxicity | Does the response contain harmful, offensive, or inappropriate content? |
The LLM call must go through a provider supported in the Integrations. If the call is proxied through an unsupported provider, auto evaluation scores will not appear.
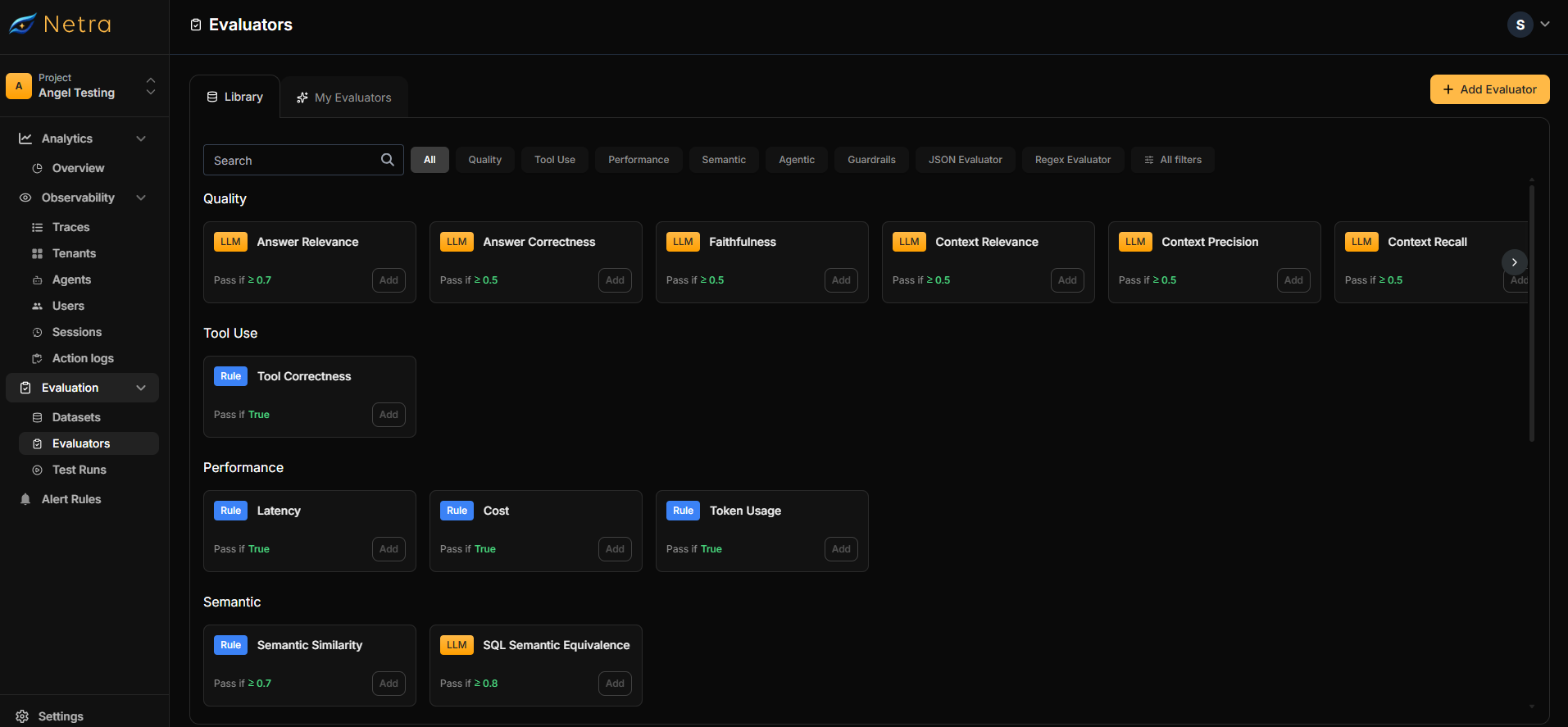
Evaluators Dashboard
Navigate to Evaluation → Evaluators from the left navigation panel. The interface has two tabs:| Tab | Description |
|---|---|
| Library | Netra’s preconfigured evaluators organized by category |
| My Evaluators | Your saved custom configurations for reuse across datasets |
Creating Custom Evaluators
Click the Add Evaluator button in the top right corner to create a new evaluator.LLM as Judge Configuration
Use LLM as Judge when you need to evaluate subjective criteria like answer quality, relevance, or helpfulness.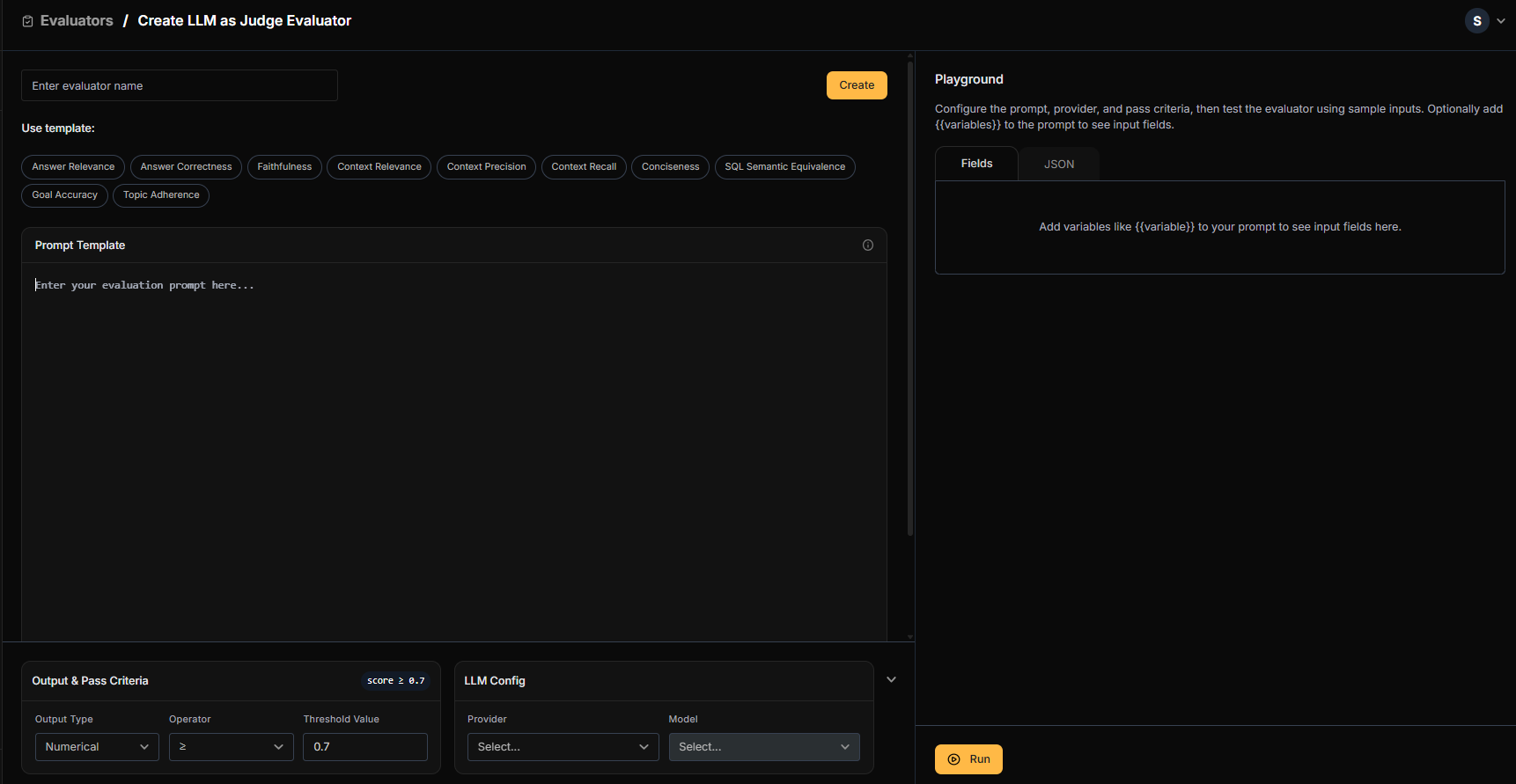
Configure Prompt Template
- Select a prebuilt template or write your own evaluation prompt
- Define variables using
{{variable_name}}syntax - Variables map to dataset fields, agent responses, or trace metadata
Set Output & Pass Criteria
| Output Type | Configuration |
|---|---|
| Numerical | Set threshold and operator (e.g., > 7 to pass) |
| Boolean | Simple pass/fail evaluation |
Select LLM Provider
Choose your preferred provider and model:
- OpenAI (GPT-4, GPT-3.5)
- Anthropic (Claude)
- Google (Gemini)
- Mistral
Code Evaluator Configuration
Use Code Evaluators for deterministic checks that don’t require AI judgment.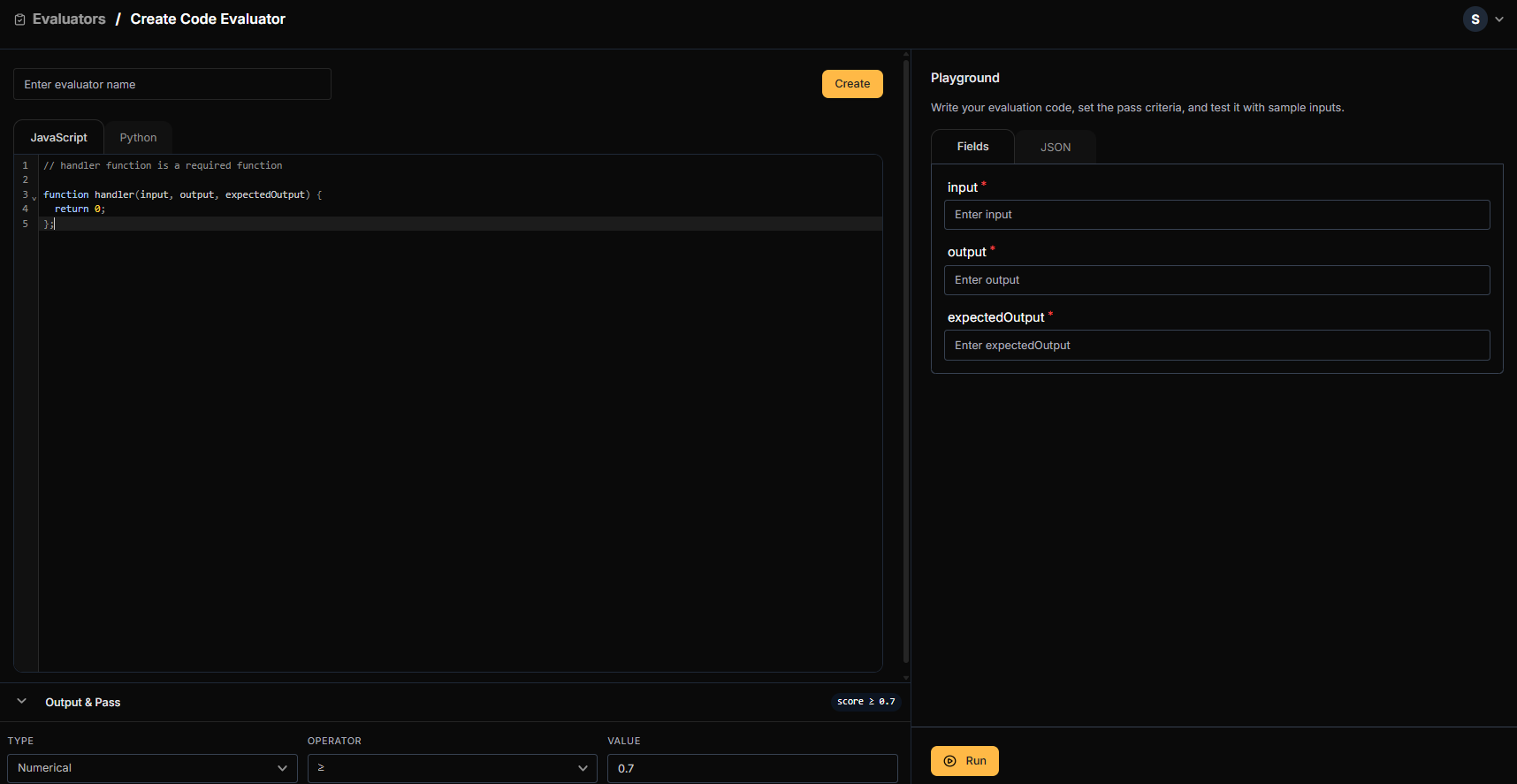
Write Your Code
Use the code editor to write JavaScript or Python. A Python example:
handler function is required.JavaScript example:Set Output & Pass Criteria
| Output Type | Configuration |
|---|---|
| Numerical | Set threshold and operator (e.g., >= 0.8 to pass) |
| Boolean | Return true/false directly from your code |
Once created, your evaluator appears in My Evaluators and becomes available when creating datasets.
Library
The Library contains pre-built evaluators ready to use or customize.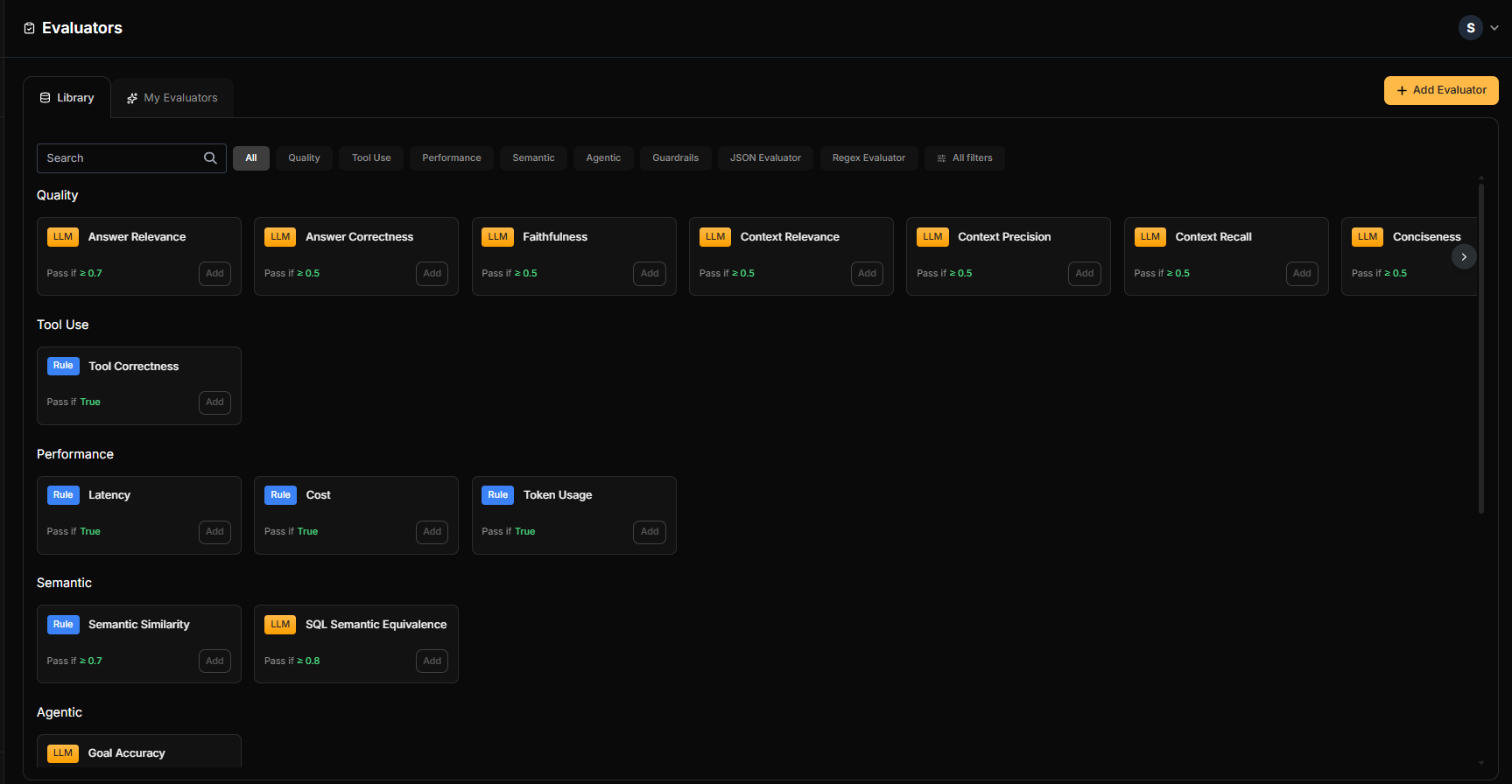
| Category | Description | Type |
|---|---|---|
| Quality | Answer correctness, relevance, completeness | LLM as Judge |
| Tool Use | Validates proper function/tool calling | LLM as Judge |
| Performance | Response time, token efficiency | Code |
| Semantic | Meaning preservation, context understanding | LLM as Judge |
| Agentic | Decision-making, multi-step reasoning | LLM as Judge |
| Guardrails | Content safety, toxicity, compliance | LLM as Judge |
| JSON Evaluator | Schema validation, structure checks | Code |
| Regex Evaluator | Pattern matching, format validation | Code |
Customizing Pre-built Evaluators
Start with a library evaluator and tailor it to your needs:Using Evaluators in Datasets
Once created, evaluators become available when building datasets:- Create or edit a dataset
- In the evaluator selection step, choose from Library or My Evaluators
- Map variables to connect evaluator inputs to your data
- Run evaluations and view results in Test Runs
Best Practices
Choosing the Right Evaluator Type
| Use Case | Recommended Type |
|---|---|
| ”Is this answer correct?” | LLM as Judge |
| ”Is the JSON valid?” | Code Evaluator |
| ”Is the response helpful?” | LLM as Judge |
| ”Does it match this regex?” | Code Evaluator |
| ”Is content safe for users?” | LLM as Judge (Guardrails) |
| “Did the agent call the right tools?” | LLM as Judge (Agentic) |
Writing Effective LLM Prompts
- Be specific: Define exactly what “correct” or “good” means
- Provide examples: Include sample inputs and expected scores
- Set clear scales: “Rate 1-10” is better than “rate quality”
- Test edge cases: Validate with ambiguous or tricky inputs
Testing Before Deployment
Always use the Playground before adding evaluators to production datasets:- Test with representative samples from your actual data
- Include edge cases and potential failure scenarios
- Verify pass/fail thresholds produce expected results
Related
- Evaluation Overview - Understand the full evaluation framework
- Datasets - Create test cases that use your evaluators
- Test Runs - View evaluation results and scores
- Quick Start: Evaluation - Get started with evaluations