Prerequisite: You need a RAG pipeline with Netra tracing configured and at least one trace visible in your dashboard. If you haven’t set this up yet, follow the Tracing a RAG Pipeline cookbook first.
What You’ll Learn
Create Datasets from Traces
Turn real RAG interactions into reusable test cases directly from the dashboard
Configure Evaluators
Set up LLM-as-Judge evaluators for retrieval quality, answer correctness, and faithfulness
Run Test Suites
Execute evaluations via the dashboard or SDK and collect quality metrics
Analyze Results & Iterate
Interpret scores, debug failures using trace integration, and improve your pipeline
Why RAG Pipelines Need Evaluation
RAG systems have multiple failure modes that are invisible without structured evaluation:| Failure Mode | What Goes Wrong | Why You Can’t Spot-Check It |
|---|---|---|
| Irrelevant retrieval | The retriever fetches chunks that don’t contain the answer | Similarity scores look reasonable, but the content is off-topic |
| Hallucination | The LLM generates information not present in the retrieved context | The answer sounds fluent and confident, but fabricates details |
| Missed intent | The answer is factually correct but doesn’t address the user’s actual question | Only noticeable when you compare against a known-good response |
| Inconsistency | The same question gets different quality answers depending on retrieved chunks | Requires running the same inputs multiple times to detect |
Now, let’s walk through the process of evaluating a RAG pipeline:
Step 1: Create Evaluators
Go to Evaluation → Evaluators and add the following three evaluators from the library:| Evaluator | What It Measures |
|---|---|
| Answer Correctness | Is the generated answer factually correct compared to the expected output? |
| Context Relevance | Are the retrieved chunks relevant to the question being asked? |
| Faithfulness | Is the answer grounded in the retrieved context, without hallucination? |
Step 2: Create a Dataset from Traces
Select a trace
Go to Observability → Traces and select a trace from the Tracing a RAG Pipeline cookbook, or any other RAG pipeline trace you have.
Add to Dataset
Click on the trace, then click Add to Dataset. Create a new dataset called “RAG Quality Dataset”.
Step 3: Add More Test Cases
Add one more trace with a different question to the same dataset by repeating the Add to Dataset flow. Under Evaluation → Datasets, you should now see the “RAG Quality Dataset” with two dataset items and three evaluators under the Evaluators tab, as shown in the video above. You can add more evaluators or dataset items manually from this page.Step 4: Trigger a Test Run
Currently in Netra, test runs are triggered via code. Copy the Dataset ID from the dataset page and use the code below.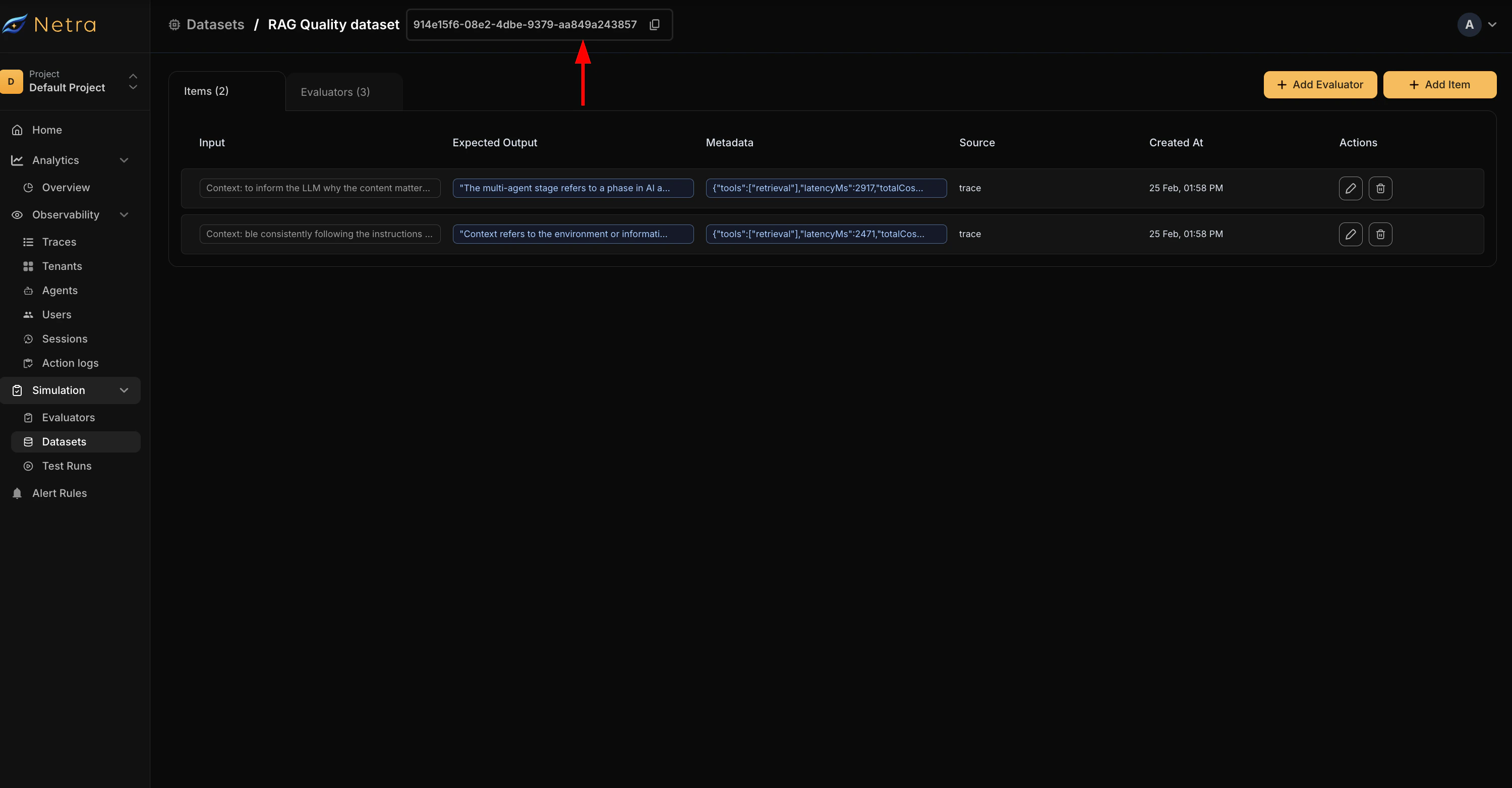
Step 5: View Results
Go to Evaluation → Test Runs to see your test run with its status. Click on the test run to see the result for each evaluator, for each dataset item — whether it passed or failed. You can also click View Trace on any result to debug what went wrong or verify what was correct. See Test Runs for the full reference.Interpreting Scores and Improving Quality
When evaluator scores are low, use this table to identify the likely cause and fix:| Low Score In | Likely Cause | How to Fix |
|---|---|---|
| Answer Relevance | Wrong chunks retrieved | Increase top_k, reduce chunk size, add overlap between chunks |
| Factual Accuracy | LLM misinterprets context | Improve the system prompt, lower temperature, use a stronger model |
| Coherence | Disjointed or repetitive response | Refine the system prompt to request structured answers |
| Faithfulness | Model hallucinating beyond context | Add explicit grounding instructions (e.g., “Only answer using the provided context”) |
Continuous Evaluation Strategy
For production RAG systems, run evaluations regularly:- On every deployment — Run your test suite in CI/CD before releasing changes to retrieval logic or prompts
- Weekly benchmarks — Track quality trends over time to catch gradual degradation
- After prompt changes — Measure the impact of system prompt modifications on all quality dimensions
- After parameter tuning — Validate that changes to chunk size,
top_k, or overlap actually improve quality
See Also
Trace Your RAG Pipeline
Set up comprehensive tracing for your RAG pipeline before evaluating
Evaluation Overview
Deep dive into Netra’s evaluation framework: datasets, evaluators, and test runs
Evaluating Agent Decisions
Evaluate tool selection, escalation, and workflow completion in agents
A/B Testing Configurations
Compare different pipeline configurations systematically